CArMA¶
CArMA is the C++ API for Massively parallel Applications. It provides a set of C++ classes for an easy integration of GPU accelerated numerical tools into complex applications.
CArMA is built on top of the CUDA toolkit from NVIDIA. CUDA provides a large collection of tools to perform scientific computing (CuFFT, CuBLAS, CuRAND). Moreover, several libraries like MAGMA have been developed using CUDA and provide additional features very useful for scientific computing.
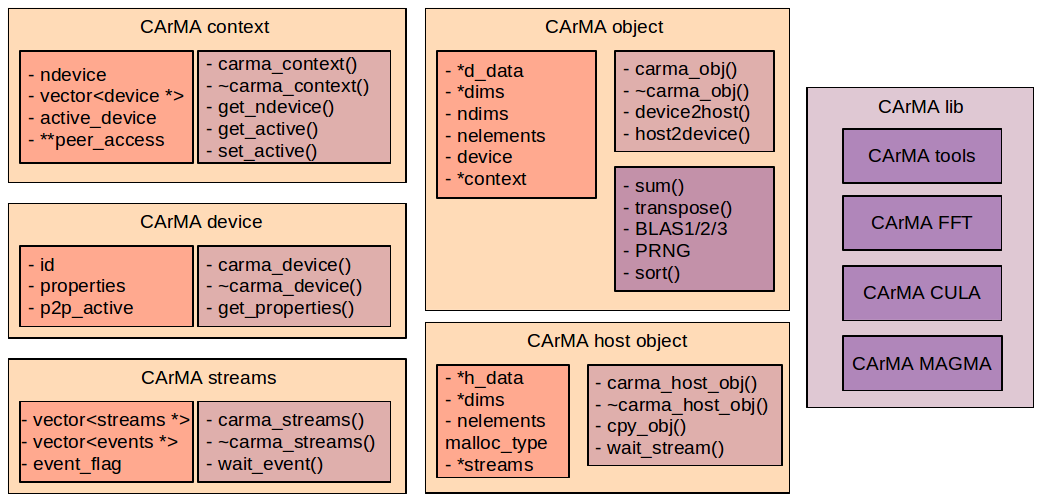
- the CArMA device providing information on a specific device
- the CArMA context itself, regrouping the information about the overall system configuration
- the CArMA streams, containers for a collection of wrappers to CUDA streams
- the CArMA object providing a container for the manipulation of data on the GPU
- the CArMA host object, providing a container for data on the system memory tagged and aligned so as to be accessed by the GPU DMA engine
Additionally, CArMA provides a set of wrappers to various libraries part of or based on the CUDA toolkit to manipulate CArMA objects and perform optimized computations.
CArMA can be used to easily build higher level applications. The SuTrA library is an exemple of such use. CArMA can also be bound to an interpreted language for a simplified access to basic GPU features. The YoGA plugin is an exemple of such use.
Mis à jour par Damien Gratadour il y a plus de 12 ans · 8 révisions